Visual abstraction as a key target for AI systems
Sketching is a powerful tool for understanding human visual abstraction—how we distill semantically relevant information from our experiences of a visually complex world. In fact, it is one of the most prolific and enduring visualization techniques in human history for conveying our ideas in visual form. (As old as 40,000-60,000 years and found in most cultures!) Perhaps this is because, even without specialized training, most people including kids can make and interpret sketches.
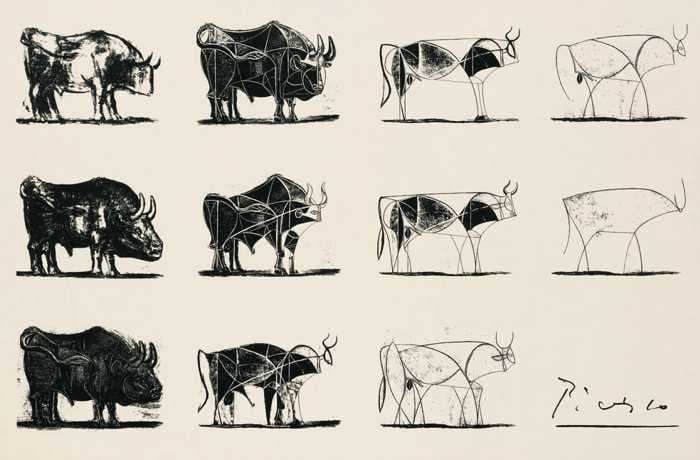
Take, for example, Picasso’s famous sketch series “The Bull” (1945). Despite some sketches being extremely sparse in details (right side) , each one is unmistakably a bull. What makes them so easily recognizable to us? Despite the fact that this ability to recognize visual concepts across levels of abstraction comes to us with such ease, it remains unclear to what extent current state-of-the-art vision algorithms are sensitive to visual abstraction in human-like ways.
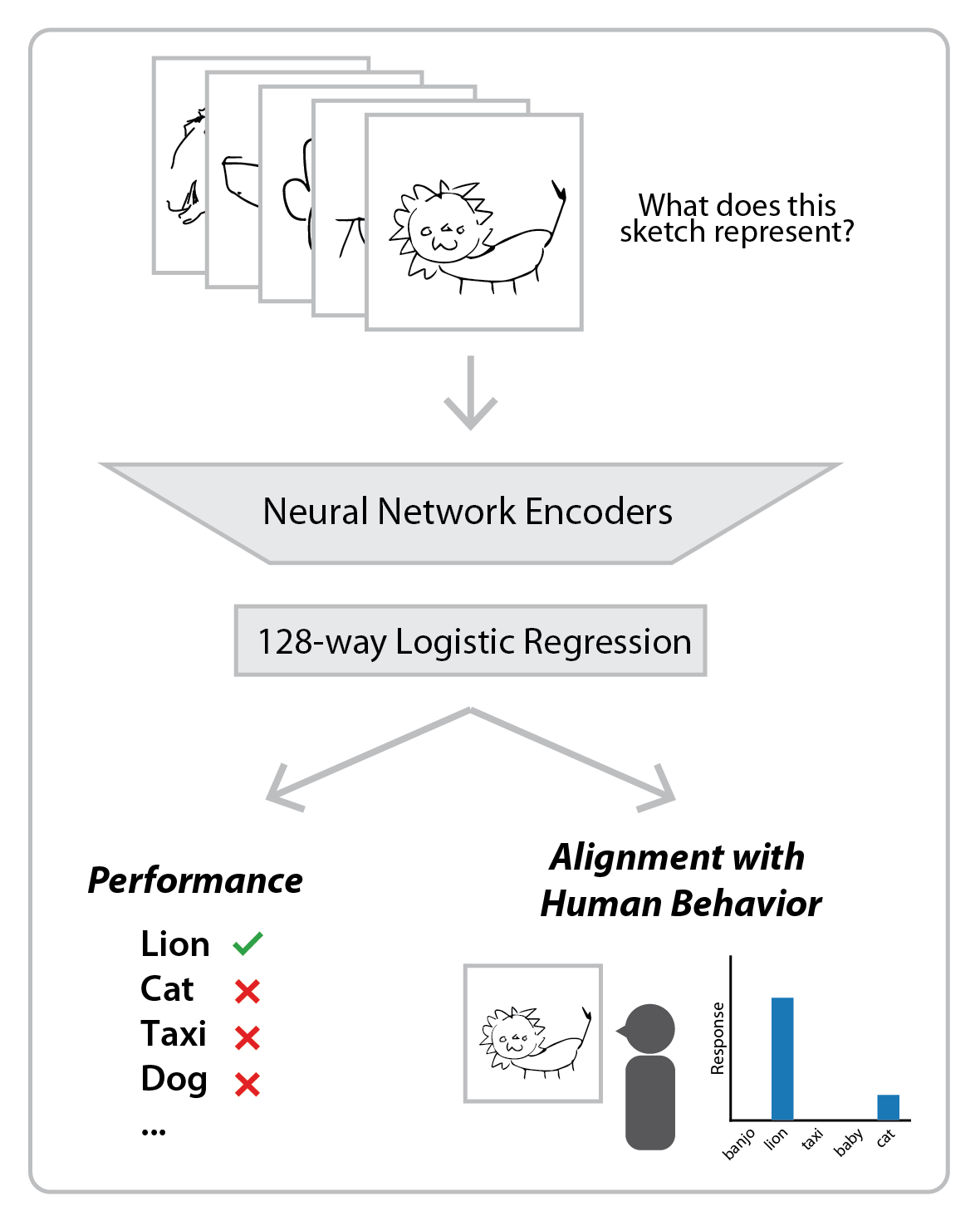
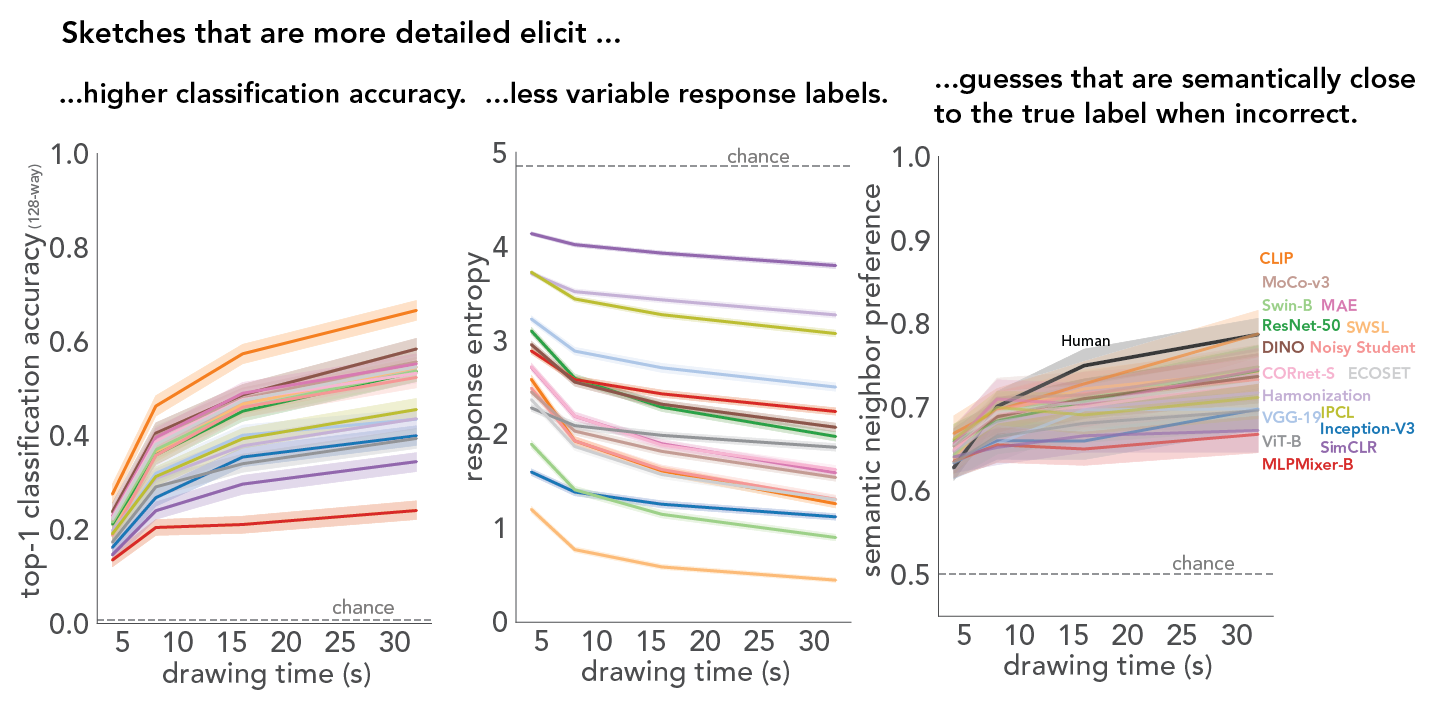
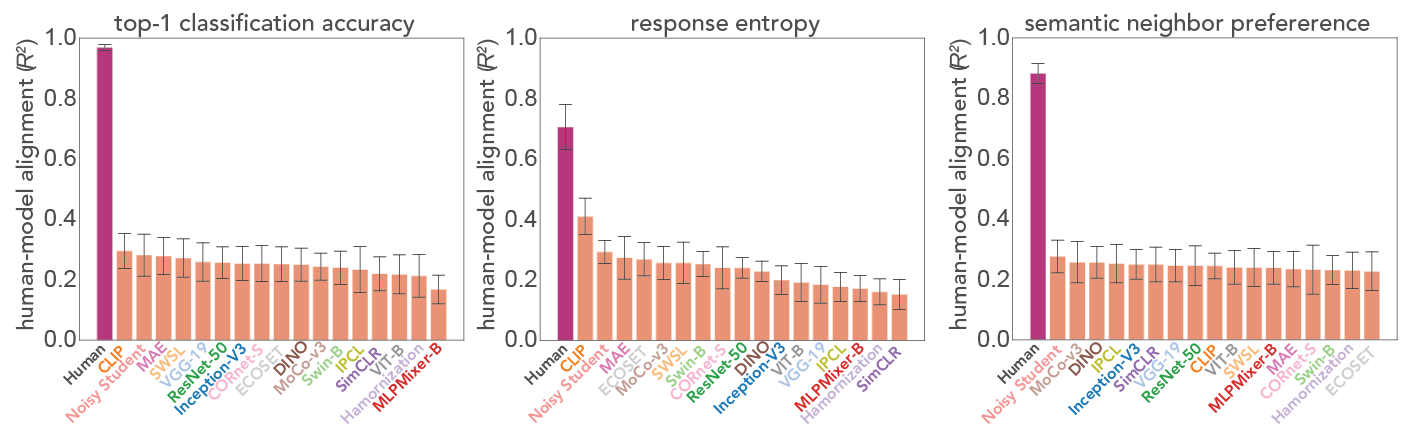
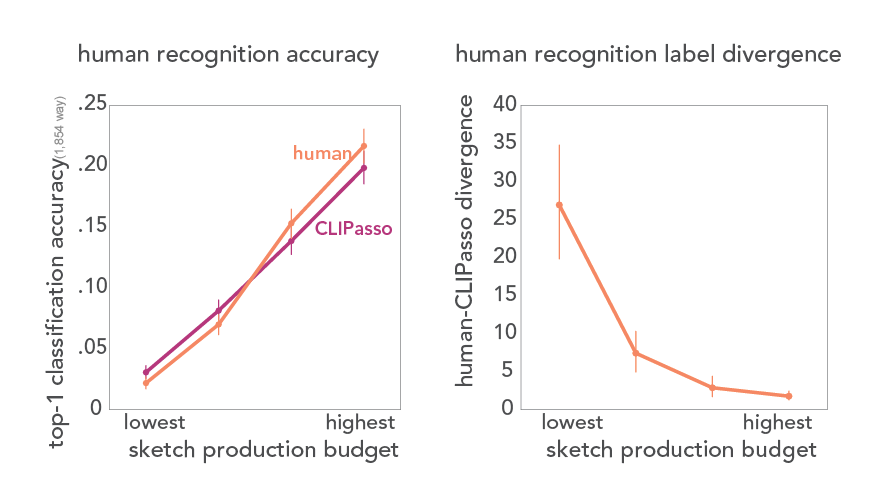
With a goal towards developing robust and generalized AI systems that can recognize sketches, diagrams, and glyphs in human-like ways, here we tackle two critical challenges: